地理信息技術 信息時代的地理學革命
地理信息技術(Geographic Information Technology, GIT)是現代信息技術與地理科學深度融合的產物,它通過計算機硬件、軟件和地理數據的結合,實現了對地球表層空間信息的采集、存儲、管理、分析和可視化。作為信息技術的重要分支,地理信息技術不僅改變了傳統地理學的研究方法,更在智慧城市、資源管理、災害監測、交通規劃等領域展現出巨大價值。
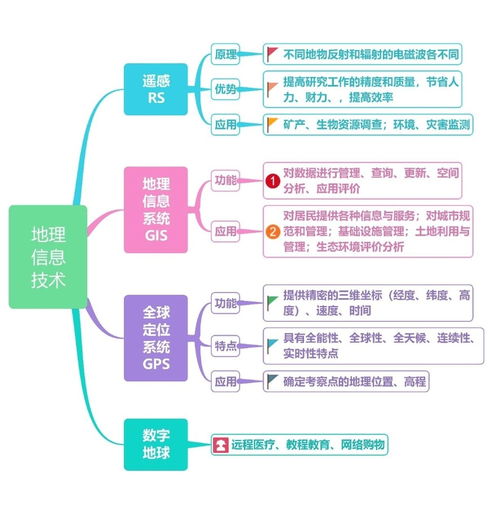
地理信息技術的核心組成包括地理信息系統(GIS)、遙感(RS)和全球定位系統(GPS)。地理信息系統負責空間數據的處理與分析,遙感技術通過衛星或航空傳感器獲取地表信息,而全球定位系統則提供精準的時空定位服務。這三者的協同工作,構成了一個完整的地理信息獲取與處理鏈條。
在信息技術飛速發展的推動下,地理信息技術正經歷著深刻變革。云計算使得海量地理數據的存儲和計算成為可能,人工智能技術提升了地理信息分析的智能化水平,5G通信技術則為實時地理信息服務提供了高速傳輸保障。與此同時,地理信息技術也在反向推動信息技術的發展,特別是在空間數據分析、可視化技術等領域產生了重要影響。
當前,地理信息技術的應用已深入各行各業。在城市規劃中,GIS技術幫助決策者進行用地分析和基礎設施布局;在環境保護領域,遙感技術實現了對植被覆蓋、水質變化的動態監測;在應急管理方面,地理信息技術為災害預警和救援指揮提供了關鍵支撐。隨著物聯網、大數據等新技術的融合,地理信息技術正朝著更精準、更智能、更實時的方向發展。
地理信息技術將與人工智能、虛擬現實等技術深度融合,構建更加智慧的數字地球。從自動駕駛的高精地圖到智慧農業的精準作業,從數字孿生城市到全球環境監測,地理信息技術將繼續拓展其應用邊界,為人類社會可持續發展提供強大技術支撐。這一融合了信息技術與地理科學的交叉領域,正在重塑我們認知和改造世界的方式。
如若轉載,請注明出處:http://www.girlxiu.cn/product/13.html
更新時間:2026-04-27 18:51:13